PiFlow(大数据流水线系统) V0.9 官方版
|
PiFlow是一款非常强大的大数据流水线系统,混合型科学大数据流水线系统,这款系统将数据采集、储存的等环节封装成组件,软件简单使用容易,提供100+的数据处理组件,如果有需要朋友的可以来本站下载试试。
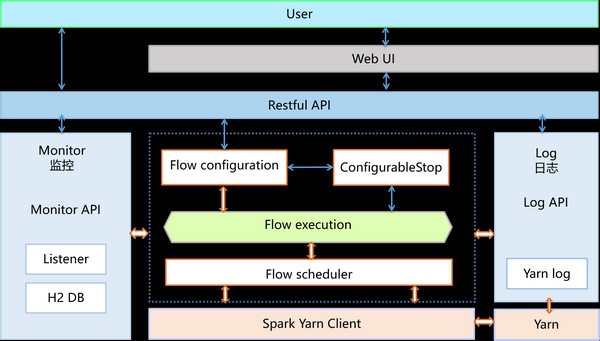
软件特色 简单易用。 可视化配置流水线。 监控流水线。 查看流水线日志。 检查点功能。 扩展性强: 支持自定义开发数据处理组件。 性能优越: 基于分布式计算引擎Spark开发。 功能强大: 提供100+的数据处理组件。 包括Hadoop 、Spark、MLlib、Hive、Solr、Redis、MemCache、ElasticSearch、JDBC、MongoDB、HTTP、FTP、XML、CSV、JSON等。 集成了微生物领域的相关算法。 使用方法 解压piflow-server-v0.9.tar.gz。 tar -zxvf piflow-server-v0.9.tar.gz。 编辑配置文件config.properties。 运行、停止、重启PiFlow Server。 start.sh、stop.sh、 restart.sh、 status.sh。 测试 PiFlow Server。 设置环境变量 PIFLOW_HOME。 vim /etc/profile。 export PIFLOW_HOME=/yourPiflowPath/bin。 export PATH=PATH:PIFLOW_HOME/bin。 运行如下命令。 piflow flow start example/mockDataFlow.json。 piflow flow stop appID。 piflow flow info appID。 piflow flow log appID。 piflow flowGroup start example/mockDataGroup.json。 piflow flowGroup stop groupId。 piflow flowGroup info groupId。 如何配置config.properties。 #spark and yarn config。 spark.master=yarn。 spark.deploy.mode=cluster。 #hdfs default file system。 fs.defaultFS=hdfs://10.0.86.191:9000。 #yarn resourcemanager.hostname。 yarn.resourcemanager.hostname=10.0.86.191。 #if you want to use hive, set hive metastore uris。 #hive.metastore.uris=thrift://10.0.88.71:9083。 #show data in log, set 0 if you do not want to show data in logs。 data.show=10。 #server port server.port=8002 #h2db port h2.port=50002 |